В нашей жизни есть много правил. Очень часто эти правила регламентированы какими-то критериями. Например, чтобы поступить в университет, нужно набрать определенное количество баллов, чтобы понести наказание за вождение в нетрезвом виде, в крови должно быть обнаружено более определенного числа промилле алкоголя, чтобы получить отличную оценку, нужно набрать критерий по теории на экзамене и так далее… Иными словами мы в своем изучении эконометрических методов столнулись с ситуацией, когда наш тритмент не просто эндогенный, он еще и может зависеть от какой-то другой континуальной переменной. Для того, чтобы решать такие задачи, был придуман дизайн разрывной регрессии.
Базовая постановка выглядит следующим образом:
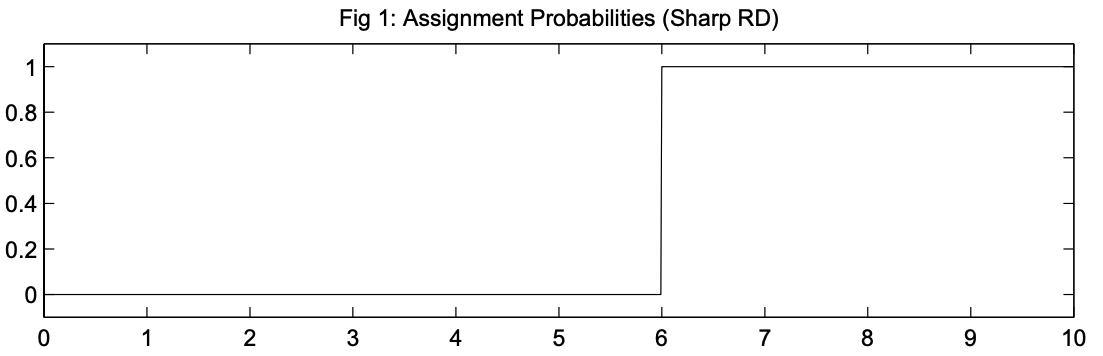
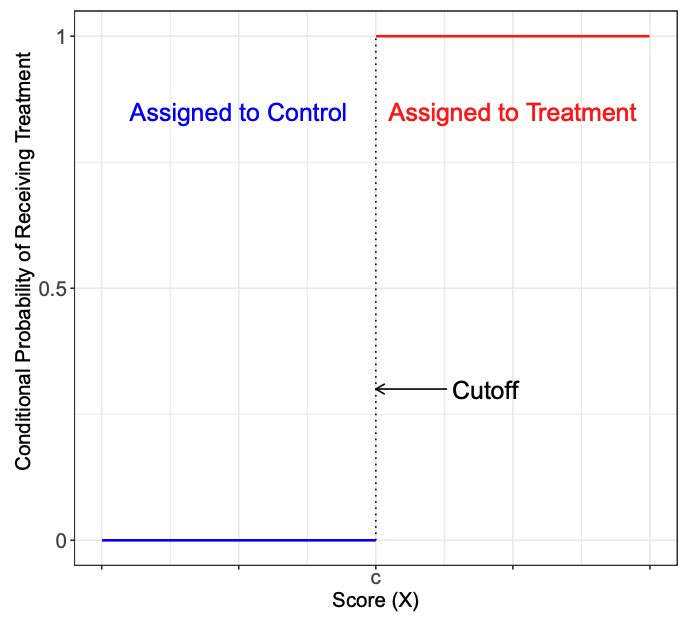
Тритмент переменная \(T\) является функцией от \(R\), такой что \(T = \mathbb{I}(R>c)\), где \(\mathbb{I}(.)\) индикаторная функция, принимающее значение 1, если выражение в скабках истинно, а \(c\) – некоторая отсечка (cutoff), после достижения которой наблюдение попадает в группу воздействия. То же самое можно записать в виде системы:
\[ T(R)= \begin{cases} 1, R>c\\ 0, R<c\\ \end{cases} \]
На рисунках ниже изображена вероятность попадания в тритмент группу. По оси абсцисс – бегущая переменная, по оси ординат – вероятность попадания в тритмент. В данном примере \(c=6\).
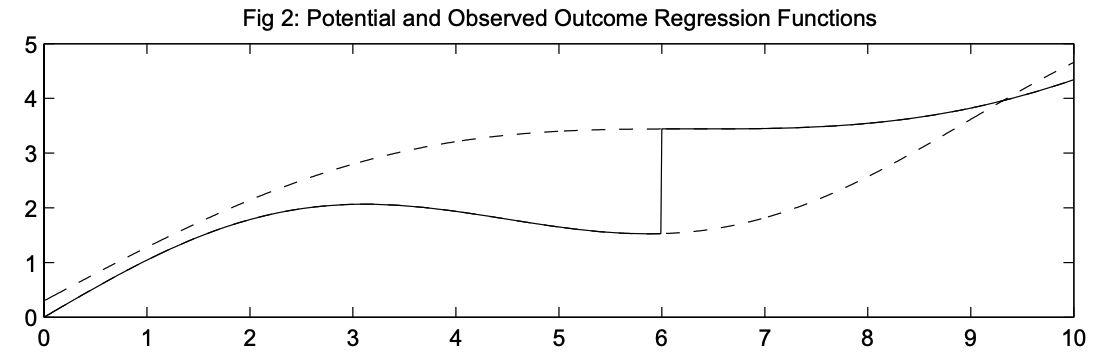
Далее обратимся к потенциальным исходам, которые обозначены ниже пунктирными линиями. Видим, что левее от отсечки по бегущей переменной реализуется \(Y_0\), правее – \(Y_1\). Таким образом, наблюдаемый \(Y\) обозначен сплошной линией. Математически это как и раньше описывается формулой \(Y = T\cdot Y_1 + (1-T)\cdot Y_0\)

Вернемся к формальному описанию предпосылок.
Заметим, что в такой ситуации мы не можем использовать другие методы, например, мэтчинг. Почему? Как раз из-за нарушения последней предпосылки, у нас просто нет для этого контрольной группы.
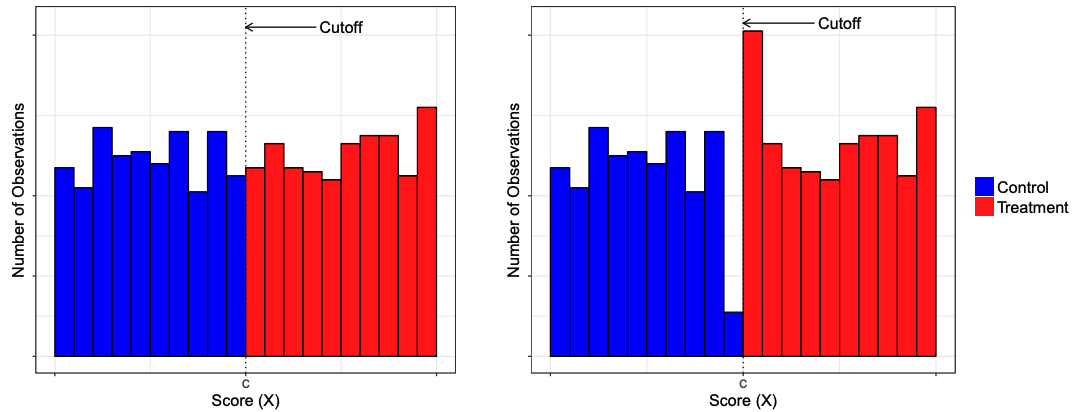
Вместо предпосылки об экзогенности тритмента выше предположим непрерывность функций \(E(Y_1|R), E(Y_0|R), E(X|R)\). Можем ли мы как-то проверить этот факт? Для потенциальных исходов, конечно, нет, мы их вовсе не наблюдаем. В непрерывность \(Y\) мы, увы просто верим и можем обосновывать её содержательными соображениями, а вот непрерывность \(X\) мы вполне можем проверить. Например, мы можем нарисовать график зависимости \(X\) от running variable. Таким образом, мы можем обоснованно заявлять, что разрыв в \(Y\) вызван изучаемым эффектом, а не каким-либо структурным сдвигом в \(X\).
Отдельно, как ниже, стоит проверить распределение количества людей относительно отсечки, чтобы обезопасить себя от проблемы самоотбора, как на картинке справа:
Далее перейдём к оценке. Как мы говорили ранее, самая сложная проблема, которая перед нами стоит – это то, что у нас нет контрольной группы. Сравнить среднее значение зависимой переменной слева от отсечки со средним значением справа будет являться плохой оценкой, потому что наблюдения будут несопоставимы и полученная разница может объясняться различиями к контрольных переменных, а не тем эффектом, который мы хотим оценить.
Эконометристы придумали следующий финт – если мы возьмём наблюдения, которые расположены достаточно близко к отсечке, то они будут похожи друг на друга по величине running variable. Промежуток по running variable, который мы выбираем вокруг отсечки называется окном, размер этого промежутка – шириной окна (bandwidth). Если мы выберем маленькое окно, то получим что-то вроде локальной рандомизации, где наша оценка будет равна обычной разнице в средних.
\[ \tau_{SRD} = \underset{R \rightarrow c+}{lim} E [Y|R] - \underset{R \rightarrow c-}{lim} E [Y|R]\]
\[ \hat{\tau}_{SRD} = \left.\overline{Y} \right|_{c<R<c+h}-\left.\overline{Y} \right|_{c-h<R<c}\]
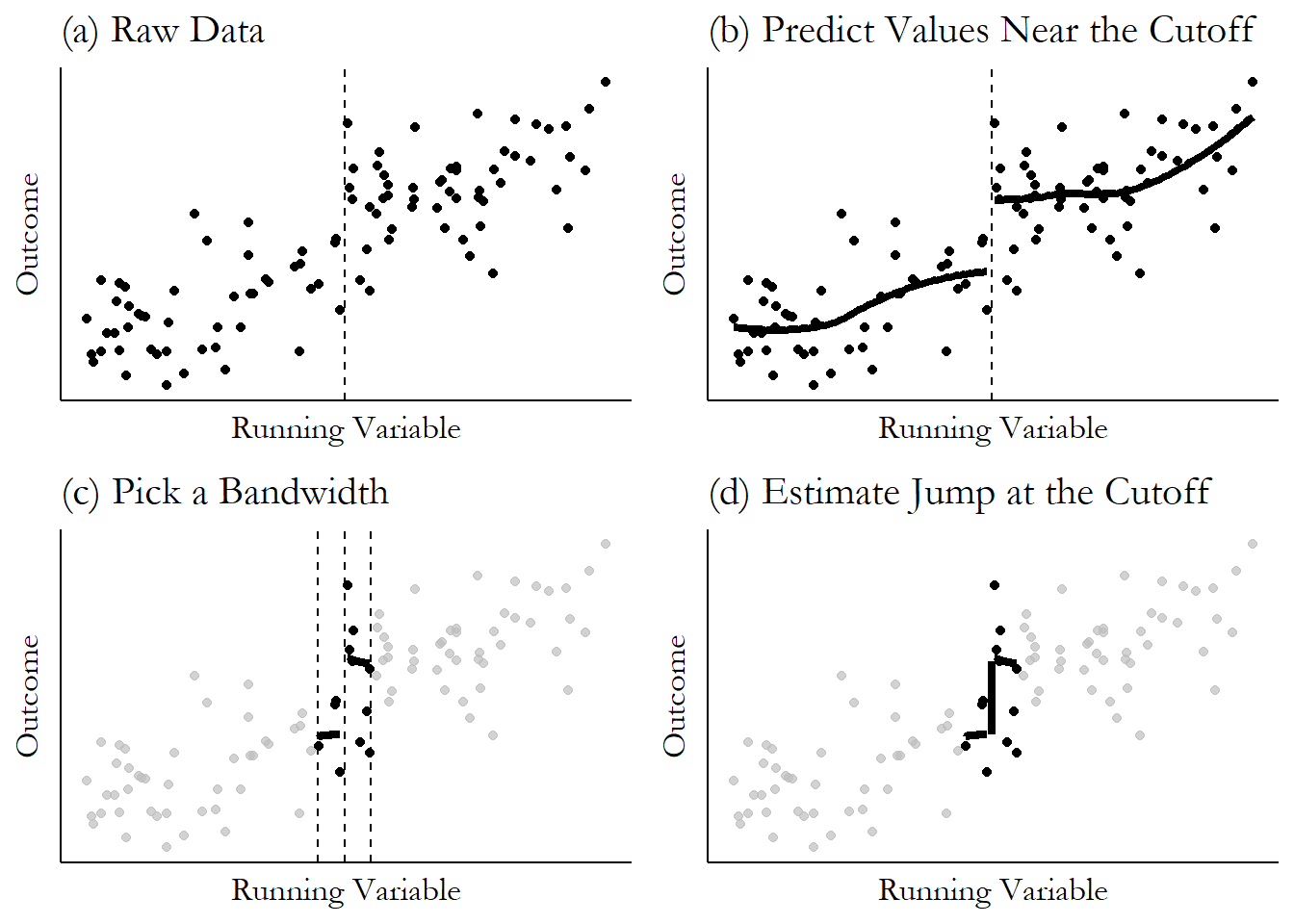
Итак, подведем итог, чтобы оценить эффект, нам сначала нужно выбрать шиину окна (обозначим её \(h\)). Затем на данных, которые лежат в пределах нашего окна \(R \in [c-h;c+h]\) считаем оценку \(\displaystyle{LATE = E(\tau|R=c) = \hat{\tau}_{SRD} = \frac{\sum \limits_{c<R<c+h} Y_i}{\sum (c<R<c+h)} - \frac{\sum \limits_{c-h<R<c} Y_i}{\sum (c-h<R<c)}}\), как и раньше это эквивалентно регресии \(\displaystyle{Y = \beta_1 + \tau \cdot T}\). Добавлять контрольные переменные можно, это позволит дополнительно снизить дисперсию оценки. Иногда еще добавляют контроль на тренд \(\displaystyle{Y = \beta_1 + \tau \cdot T + \beta_2 \cdot R + \beta_3 \cdot T \cdot R}\).
Важно отметить, что чем более широкое окно мы возьмём, тем больше наблюдений мы захватим и тем более точную оценку с меньшей дисперисей мы получим (и с более узким доверительным интервалом, что хорошо!), однако если взять слишком широкое окно, то это чревато тем, что мы захватим слишком непохожие друг на друга наблюдения и наша оценка получится смещенной. Верно и обратно, чем меньше окно, тем меньше вероятность нарваться на смещение, однако дисперсия оценки (и доверительный интервал) с маленьким окном будет выше:
Существует некоторое дополнение метода, связанное с перевзвешиванием данных. Мы предположили, что наблюдения, которые находятся внутри выбранного нами окна, достаточно похожи друг на друга, чтобы мы могли их сравнивать. Однако чем ближе наблюдения к отсечке, тем больше они похожи друг на друга. Может стоит придавать им больший вес? Для этого были придуманы оценки с помощью ядер (по сути взвешенный МНК). Некоторые из них нарисованы на рисунке ниже.

Тогда задача МНК примет вид:
\[ \hat{\mathbb{\beta}} = \underset{\beta_0, \beta_1, \beta_2, \tau}{\operatorname{argmin}} ESS = \underset{\beta_0, \beta_1, \beta_2, \tau}{\operatorname{argmin}} \sum_{i=1}^n\left[\left(y_i-\hat{\beta}_0-\hat{\beta}_1 R_i-\hat{\tau} T_i-\beta_2 T_i R_i\right)^2\right. \cdot \left.K\left(\frac{R_i-c}{h}\right)\right]\]
где \(K(.)\) – функция плотности ядерной оценки.
Например, если мы хотим для всех наблюдений использовать одинаковые веса, то мы используем равномерное распределение, функция плотности которого равна:
\[K\left(\frac{R_i-c}{h}\right)=\left\{\begin{array}{l} \frac{1}{2 h}, \text{внутри окна} \\ 0, \text{вне окна} \end{array}\right.\]
Одним из вопросов государственной политики является вопрос о том, каким должен быть минимальный возраст, с которого разрешается продавать алкоголь.В большинстве стран этот возраст установлен на уровне 18 лет, но в США (в большинстве штатов) в настоящее время он составляет 21 год.
Проявляют ли США чрезмерную осторожность? Можно ли снизить допустимый возраст до 18 лет? Или это тот случай, когда другие страны должны повысить границу минимального возраста употребления алкоголя?
Один из способов ответить на этот вопрос – оценить ситуацию с точки зрения уровня смертности (Carpenter and Dobkin, 2009). С точки зрения государственной политики можно утверждать, что мы должны максимально снизить уровень смертности. Если потребление алкоголя значительно увеличивает смертность, нам следует избегать снижения минимального возраста употребления алкоголя.
Чтобы оценить влияние алкоголя на смертность, мы могли бы использовать тот факт, что возраст, в котором разрешено употребление алкоголя, создает разрыв. В США люди младше 21 года не пьют (или пьют гораздо меньше), а те, кому чуть больше 21 года, пьют. Это означает, что вероятность пьянства резко возрастает в возрасте 21 года, и это то, что мы можем исследовать с помощью RDD.
Для начала импортируем данные из статьи (Carpenter and Dobkin, 2009):
library(foreign)
data <- read.dta("regression_discontinuity_data/AEJfigs.dta")Имеем следующие переменные:
library(stargazer)
stargazer(data, type = "text")
=====================================================
Statistic N Mean St. Dev. Min Max
-----------------------------------------------------
agecell 50 21.000 1.127 19.068 22.932
all 48 95.673 3.831 88.428 105.268
allfitted 50 95.803 3.286 91.706 102.892
internal 48 20.285 2.254 15.977 24.373
internalfitted 50 20.281 1.995 16.738 24.044
external 48 75.387 2.986 71.341 83.331
externalfitted 50 75.522 2.270 73.158 81.784
alcohol 48 1.257 0.350 0.639 2.519
alcoholfitted 50 1.267 0.260 0.794 1.817
homicide 48 16.912 0.730 14.948 18.411
homicidefitted 50 16.953 0.453 16.261 17.762
suicide 48 12.352 1.063 10.889 14.832
suicidefitted 50 12.363 0.760 11.592 13.547
mva 48 31.623 2.385 26.855 36.385
mvafitted 50 31.680 2.003 27.868 34.818
drugs 48 4.250 0.616 3.202 5.565
drugsfitted 50 4.255 0.521 3.449 5.130
externalother 48 9.599 0.748 7.973 11.483
externalotherfitted 50 9.610 0.465 8.388 10.353
-----------------------------------------------------Сначала оценим эффект вручную с помощью МНК без использования ядер, затем воспользуемся специальным пакетом.
Для этого создадим тритмент переменную на основе отсечки и переменную квадрата возраста (наверняка вы уже встречались с примерами, когда зависимость от возраста бывает квадратичной, то есть существует какой-то минимальный или максимальный возраст в зависимости \(Y\) от \(X\)):
data$T <- data$agecell>=21
data$age2 <- data$agecell^2Далее нам нужно ограничить данные окном. Предположительно выберем окно шириной в один год. Далее пакет нам посчитает оптимальную ширину окна, а пока сделаем пробный вариант. Для этого отфильтруем наши данные по окну:
library(dplyr)
data_h <- data %>% filter(agecell>20 & agecell<22)Теперь непосредственно регрессия:
mod_ols <- lm(all ~ agecell + T, data = data_h)
summary(mod_ols)
Call:
lm(formula = all ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-4.2577 -1.1736 0.0033 1.2509 3.9358
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 160.094 34.860 4.592 0.000158 ***
agecell -3.256 1.700 -1.916 0.069094 .
TTRUE 9.753 1.934 5.043 5.41e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.362 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.7029, Adjusted R-squared: 0.6746
F-statistic: 24.84 on 2 and 21 DF, p-value: 2.924e-06Получили, что смертность людей старше 21 года на 9.8 выше, чем среди людей моложе 21.
Тот же результат, но графически:
library(ggplot2)
ggplot(data_h, aes(x = agecell, y = all, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")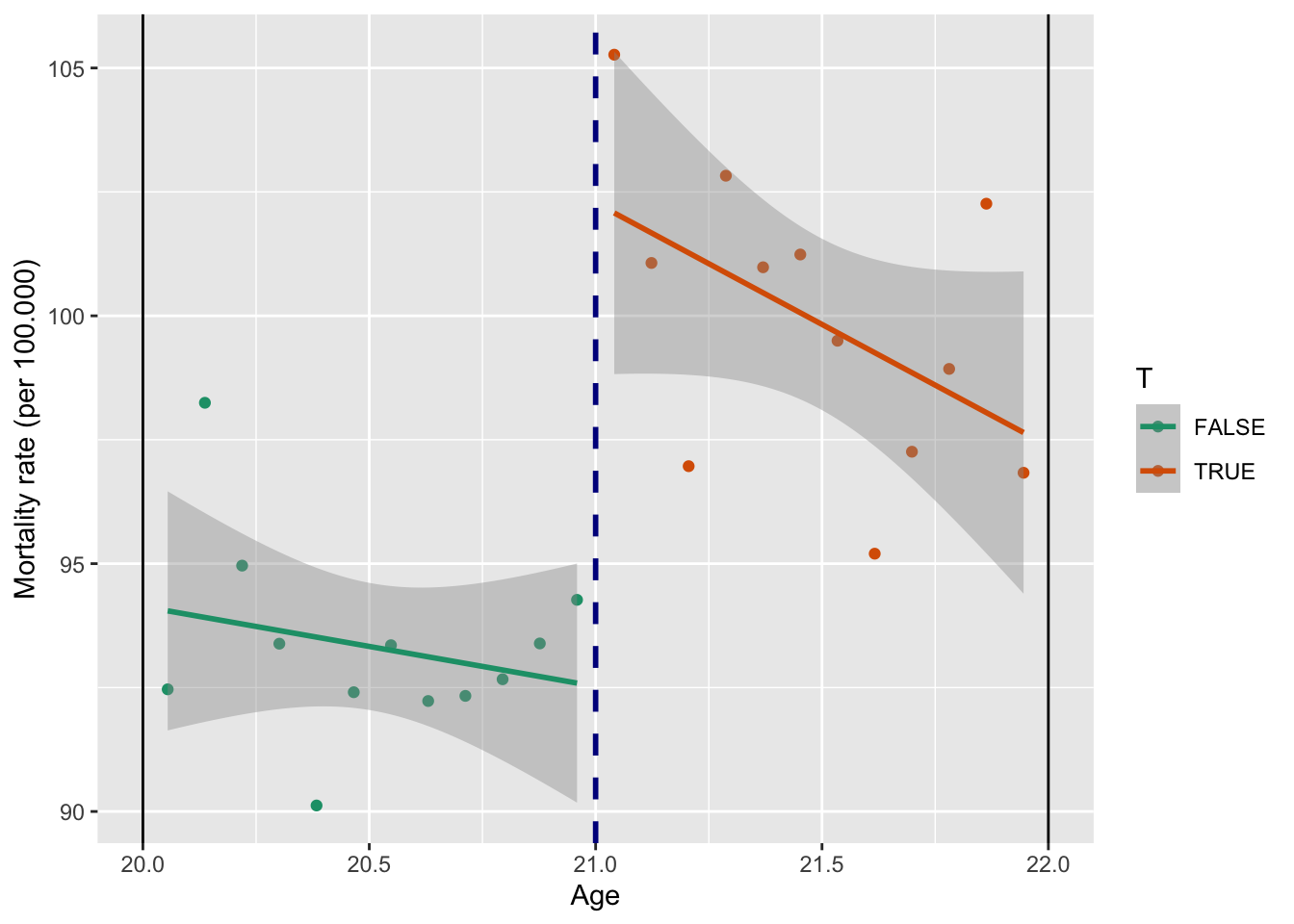
Посмотрим то же самое, но теперь еще добавим квадрат возраста:
mod_ols2<-lm(all ~ agecell + age2 + T, data = data_h)
summary(mod_ols2)
Call:
lm(formula = all ~ agecell + age2 + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-4.2063 -1.0465 -0.1178 1.0289 4.1069
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -242.2799 749.5323 -0.323 0.750
agecell 35.0933 71.3774 0.492 0.628
age2 -0.9131 1.6990 -0.537 0.597
TTRUE 9.7533 1.9676 4.957 7.59e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.403 on 20 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.7071, Adjusted R-squared: 0.6632
F-statistic: 16.09 on 3 and 20 DF, p-value: 1.473e-05ggplot(data_h, aes(x = agecell, y = all, color = T)) +
geom_point() +
geom_smooth(method = "lm",
formula = y ~ x + I(x ^ 2)) +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")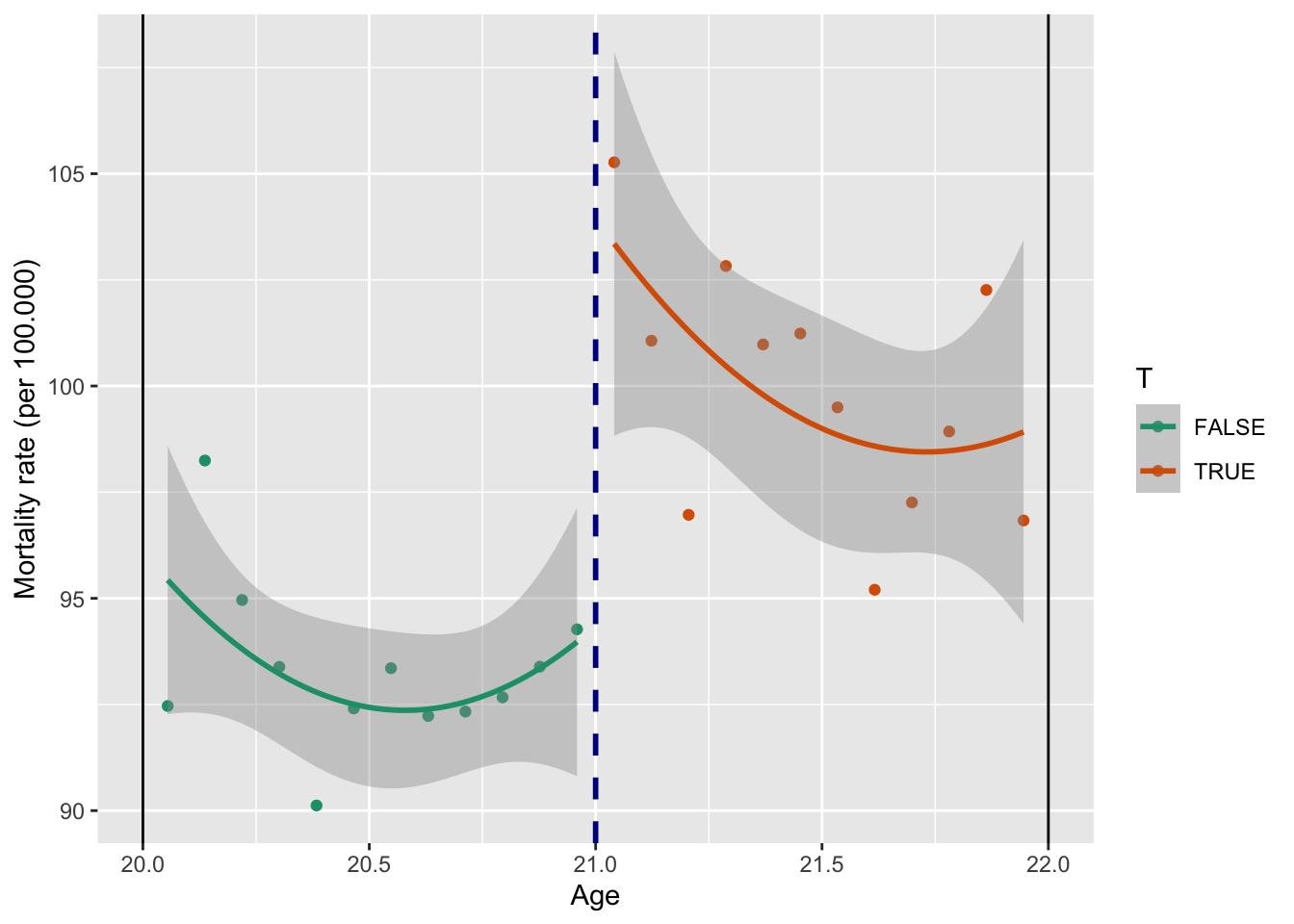
Мы поняли, что разрыв точно есть и он значим. Поробуем разобраться за счет каких причин он происходит.
mod_internal<-lm(internal ~ agecell + T, data = data_h)
summary(mod_internal)
Call:
lm(formula = internal ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-1.92574 -0.62316 0.07478 0.72291 1.38703
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.686485 13.438734 1.465 0.1578
agecell -0.009418 0.655204 -0.014 0.9887
TTRUE 1.692263 0.745552 2.270 0.0339 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9107 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.4938, Adjusted R-squared: 0.4456
F-statistic: 10.24 on 2 and 21 DF, p-value: 0.0007851ggplot(data_h, aes(x = agecell, y = internal, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")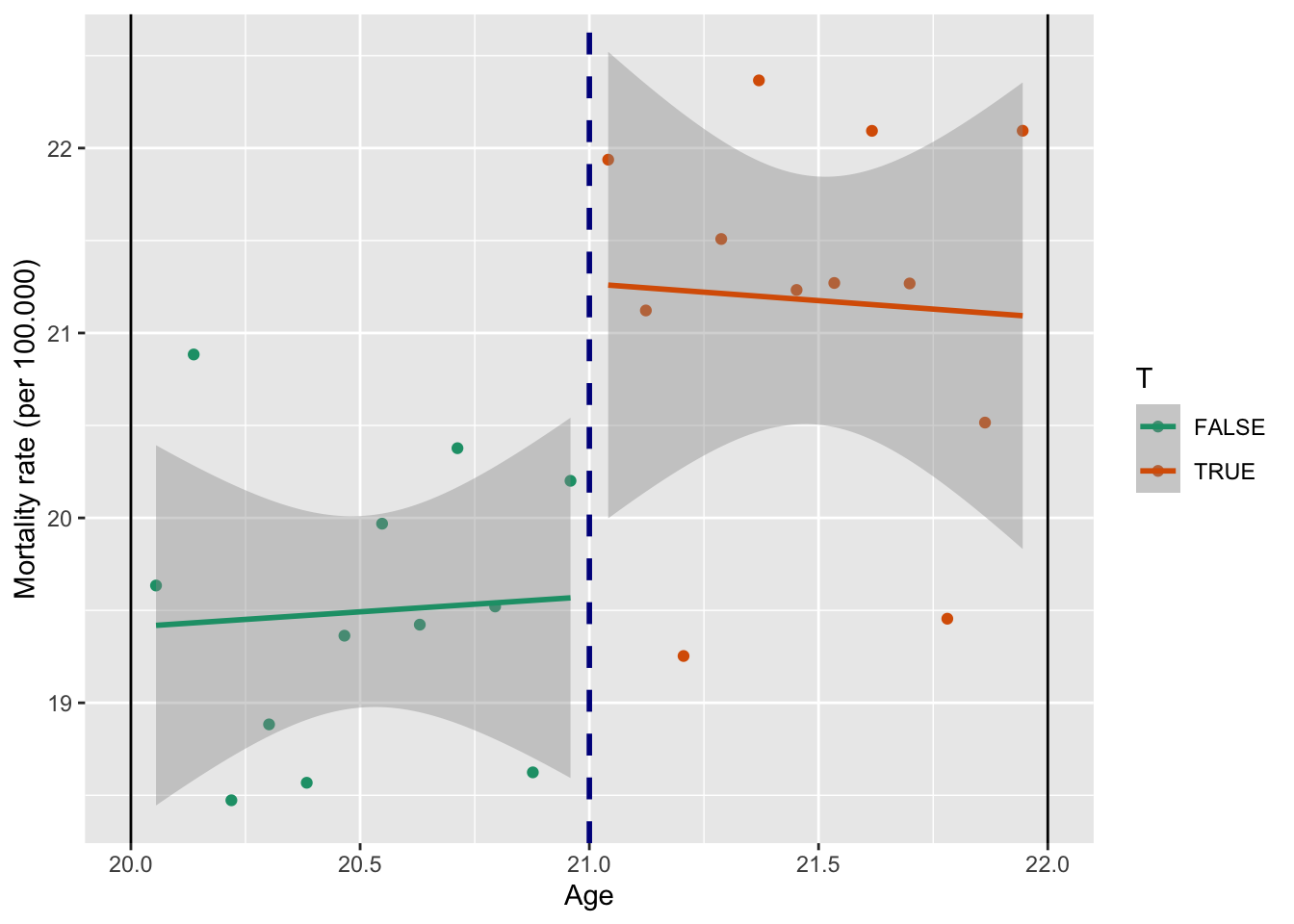
Разыв маленький (гораздо меньше общего) и значим только на 5% уровне.
mod_external <- lm(external ~ agecell + T, data = data_h)
summary(mod_external)
Call:
lm(formula = external ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-5.1759 -1.3786 -0.1486 1.7247 4.2633
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 140.408 33.698 4.167 0.000436 ***
agecell -3.247 1.643 -1.976 0.061409 .
TTRUE 8.061 1.869 4.312 0.000308 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.284 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.5967, Adjusted R-squared: 0.5582
F-statistic: 15.53 on 2 and 21 DF, p-value: 7.236e-05ggplot(data_h, aes(x = agecell, y = external, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")
Видим, что общая смертность преимущественно объясняется разрывом в смертности от внешних причин, то есть гипотеза про последствия от снижения минимального возраста продажи алкоголя пока не отвергается. Рассмотрим за счет каких причин возникает разрыв в смертности от внешних причин.
Преимущественно это алкоголь и ДТП.
Алкоголь
mod_alcohol <- lm(alcohol ~ agecell + T, data = data_h)
summary(mod_alcohol)
Call:
lm(formula = alcohol ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-0.4320 -0.1958 -0.0712 0.1912 0.8790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.7760 4.2741 1.819 0.08315 .
agecell -0.3268 0.2084 -1.568 0.13177
TTRUE 0.7405 0.2371 3.123 0.00515 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2897 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.4161, Adjusted R-squared: 0.3605
F-statistic: 7.481 on 2 and 21 DF, p-value: 0.003522ggplot(data_h, aes(x = agecell, y = alcohol, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")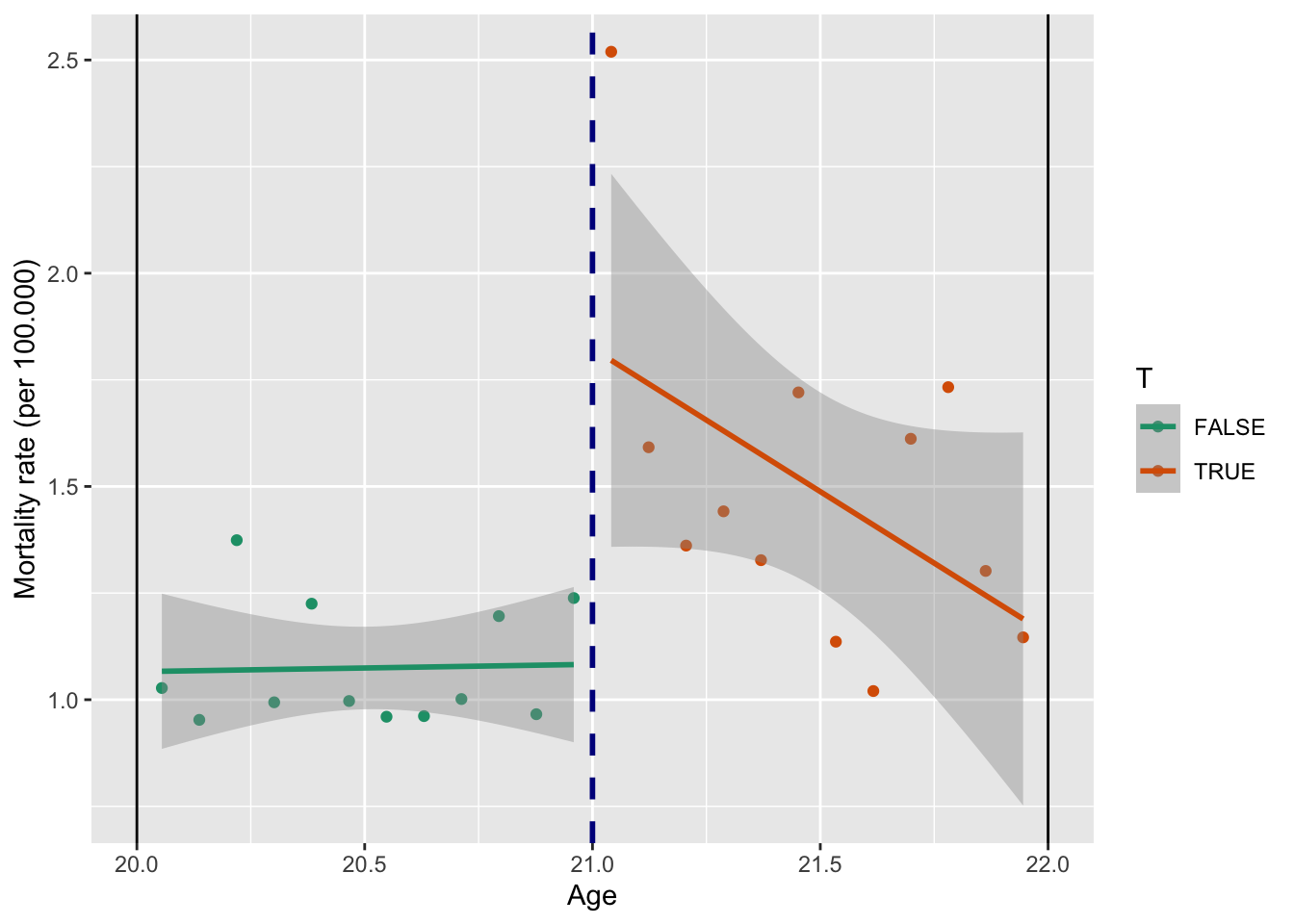
Убийства
mod_homicide <- lm(homicide ~ agecell + T, data = data_h)
summary(mod_homicide)
Call:
lm(formula = homicide ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-1.13706 -0.35555 0.03508 0.35236 1.08442
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.4593 9.8133 1.270 0.218
agecell 0.2211 0.4784 0.462 0.649
TTRUE 0.1638 0.5444 0.301 0.766
Residual standard error: 0.665 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.09453, Adjusted R-squared: 0.008298
F-statistic: 1.096 on 2 and 21 DF, p-value: 0.3525ggplot(data_h, aes(x = agecell, y = homicide, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")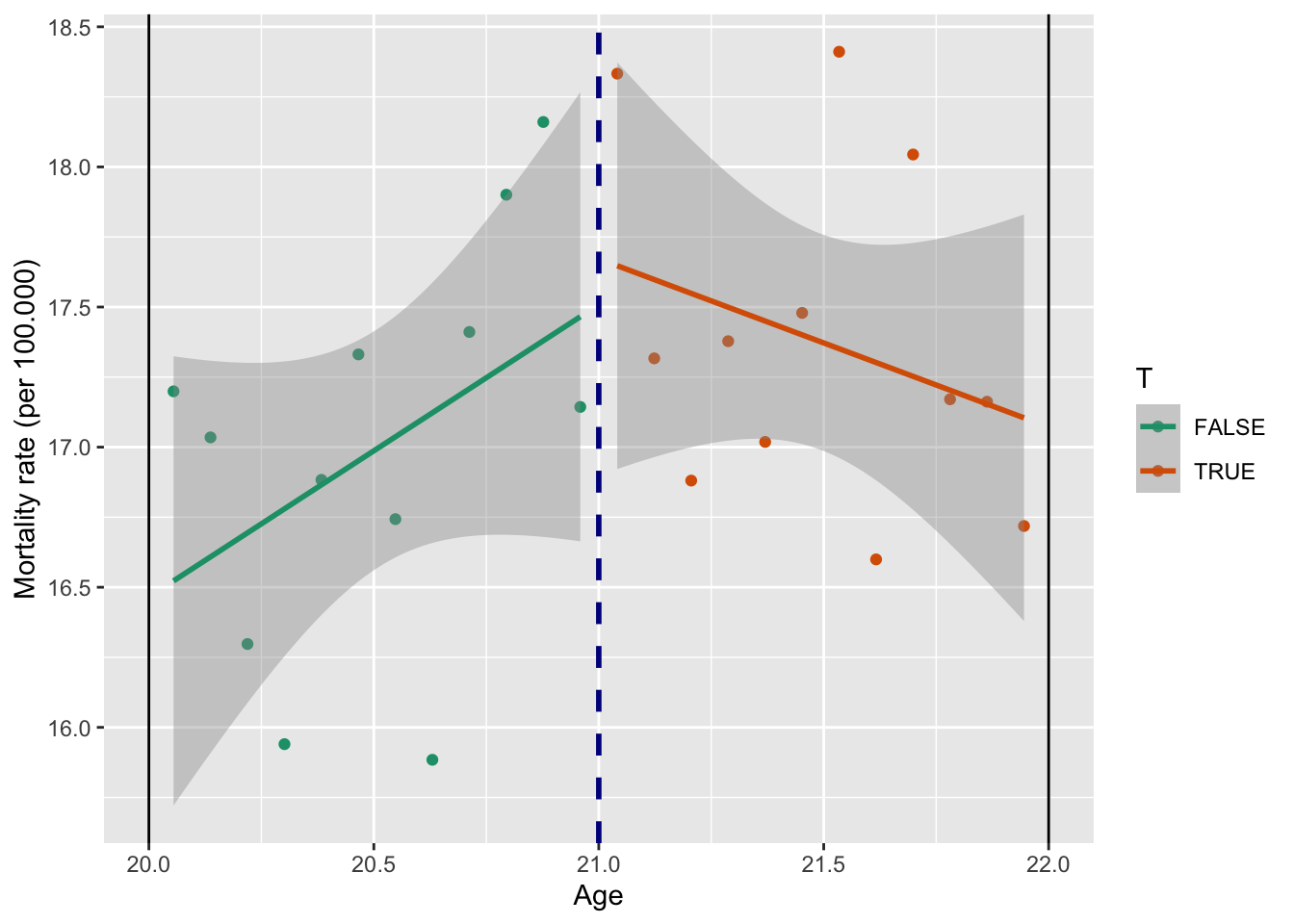
Самоубийства
mod_suicide <- lm(suicide ~ agecell + T, data = data_h)
summary(mod_suicide)
Call:
lm(formula = suicide ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-1.54946 -0.57179 0.09345 0.56743 1.46789
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.754110 12.491886 0.941 0.3574
agecell -0.005422 0.609040 -0.009 0.9930
TTRUE 1.724426 0.693023 2.488 0.0213 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8466 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.5409, Adjusted R-squared: 0.4972
F-statistic: 12.37 on 2 and 21 DF, p-value: 0.0002819ggplot(data_h, aes(x = agecell, y = suicide, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")
ДТП
mod_mva <- lm(mva ~ agecell + T, data = data_h)
summary(mod_mva)
Call:
lm(formula = mva ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-2.1088 -0.8810 -0.3918 0.7157 3.1297
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 102.4206 19.7941 5.174 3.98e-05 ***
agecell -3.4683 0.9651 -3.594 0.001708 **
TTRUE 4.7593 1.0981 4.334 0.000292 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.341 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.4736, Adjusted R-squared: 0.4234
F-statistic: 9.445 on 2 and 21 DF, p-value: 0.001186ggplot(data_h, aes(x = agecell, y = mva, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")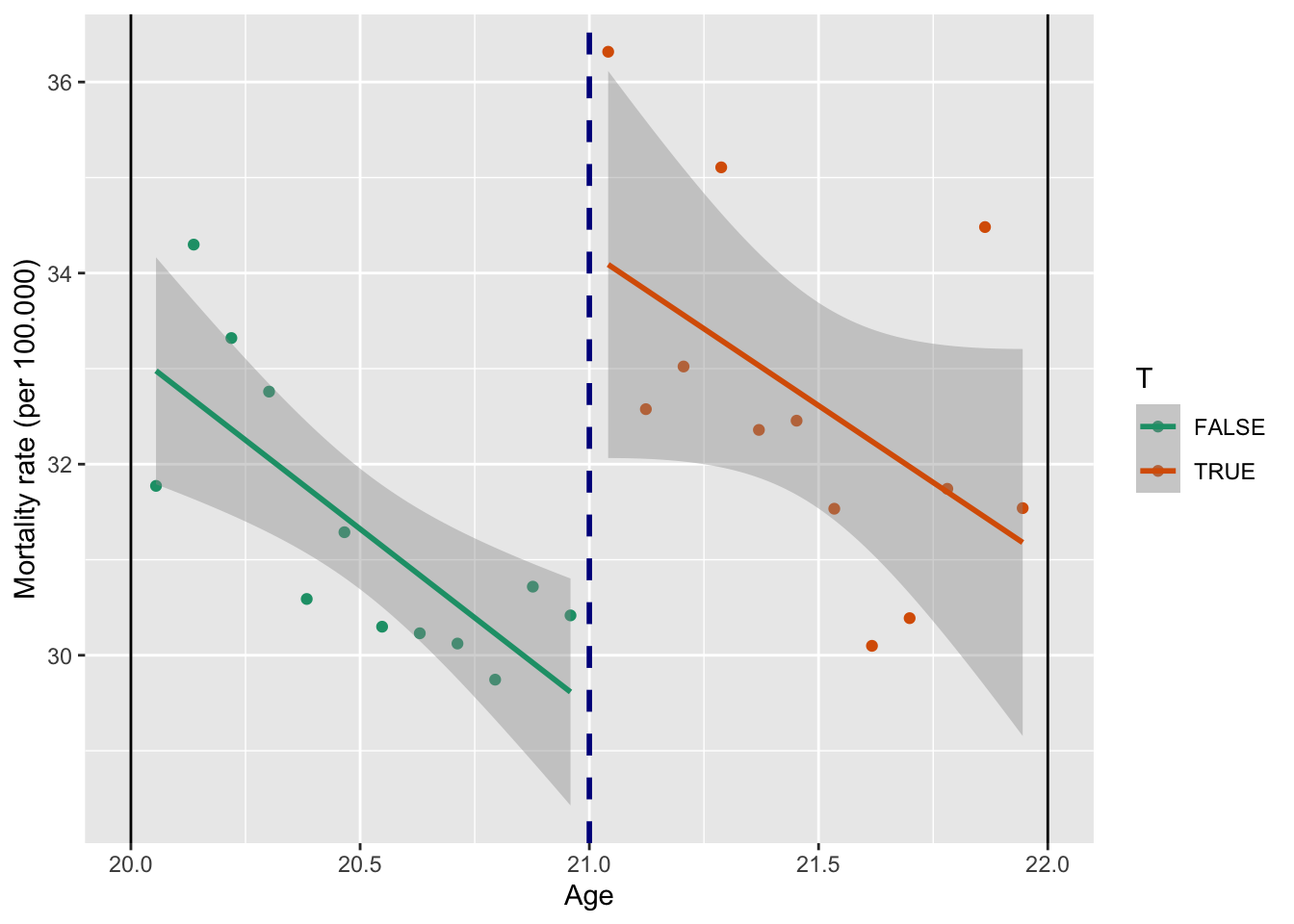
Наркотики
mod_drugs <- lm(drugs ~ agecell + T, data = data_h)
summary(mod_drugs)
Call:
lm(formula = drugs ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-0.62926 -0.27343 0.02269 0.29434 0.42476
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4.9942 4.9216 -1.015 0.3218
agecell 0.4355 0.2400 1.815 0.0838 .
TTRUE 0.2065 0.2730 0.756 0.4578
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3335 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.5446, Adjusted R-squared: 0.5013
F-statistic: 12.56 on 2 and 21 DF, p-value: 0.0002587ggplot(data_h, aes(x = agecell, y = drugs, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")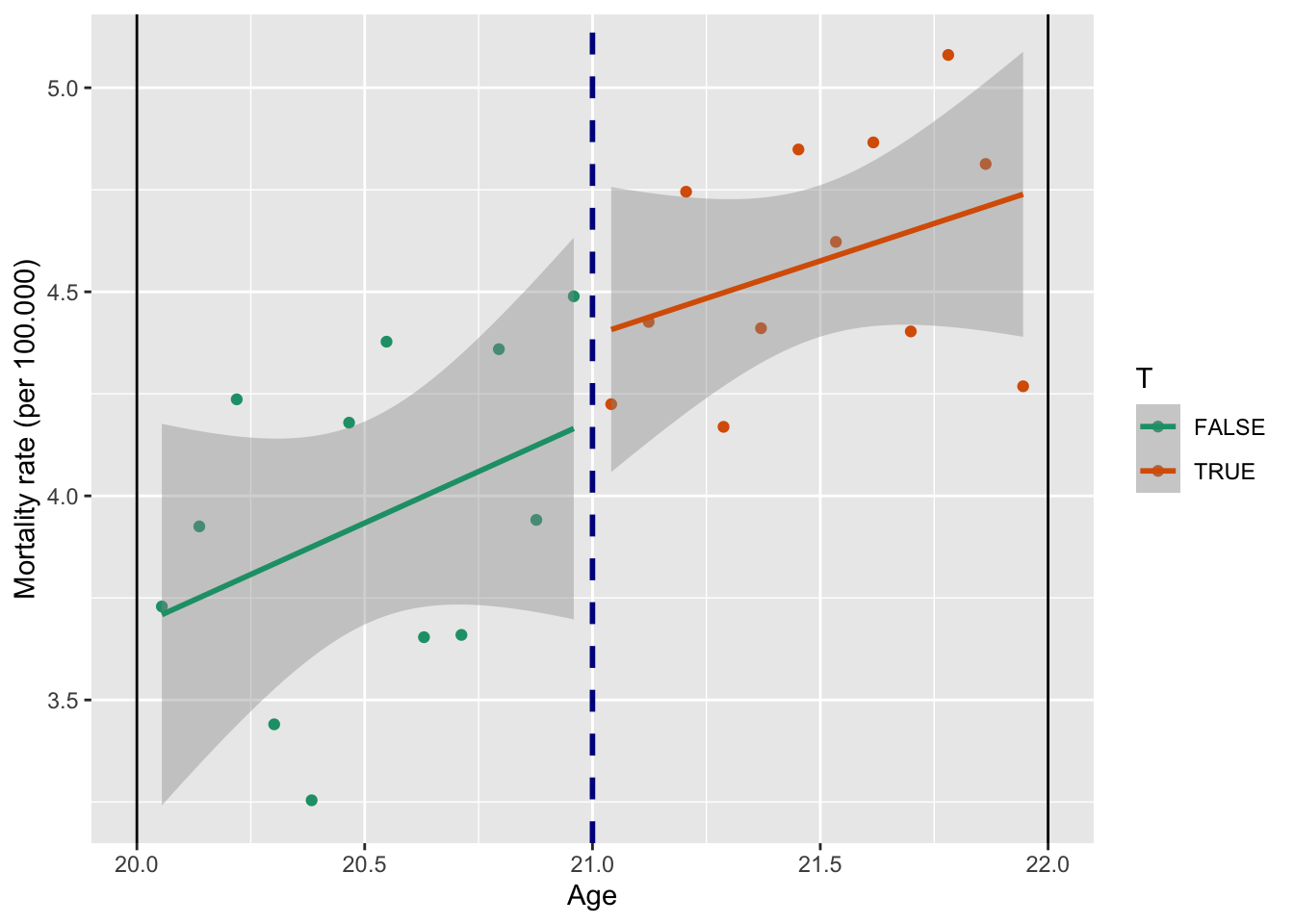
Прочие внешние причины
mod_externalother <- lm(externalother ~ agecell + T, data = data_h)
summary(mod_externalother)
Call:
lm(formula = externalother ~ agecell + T, data = data_h)
Residuals:
Min 1Q Median 3Q Max
-1.14575 -0.38546 -0.00161 0.35788 0.85794
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 13.1630 7.8140 1.685 0.107
agecell -0.1856 0.3810 -0.487 0.631
TTRUE 0.8308 0.4335 1.917 0.069 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5295 on 21 degrees of freedom
(2 observations deleted due to missingness)
Multiple R-squared: 0.305, Adjusted R-squared: 0.2388
F-statistic: 4.608 on 2 and 21 DF, p-value: 0.02192ggplot(data_h, aes(x = agecell, y = externalother, color = T)) +
geom_point() +
geom_smooth(method = "lm") +
scale_color_brewer(palette = "Dark2") +
geom_vline(xintercept = 21, color = "darkblue", size = 1, linetype = "dashed") +
geom_vline(xintercept = 20) +
geom_vline(xintercept = 22) +
labs(y = "Mortality rate (per 100.000)",
x = "Age")
Теперь та же оценка, но с помощью специального пакета, где можно выбрать ядра и ширину окна.
Мы можем установить любое окно вручную, используя аргумент bw, а также ядро с помощью аргумента kernel:
library(rdd)
mod_rdd <- RDestimate(all ~ agecell, data=data, cutpoint = 21, bw = 1)
summary(mod_rdd)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
bw = 1)
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 1.0 24 9.700 1.932 5.022 5.112e-07
Half-BW 0.5 12 9.567 2.118 4.517 6.283e-06
Double-BW 2.0 48 8.381 1.345 6.232 4.603e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 26.74 3 20 6.711e-07
Half-BW 15.27 3 8 2.257e-03
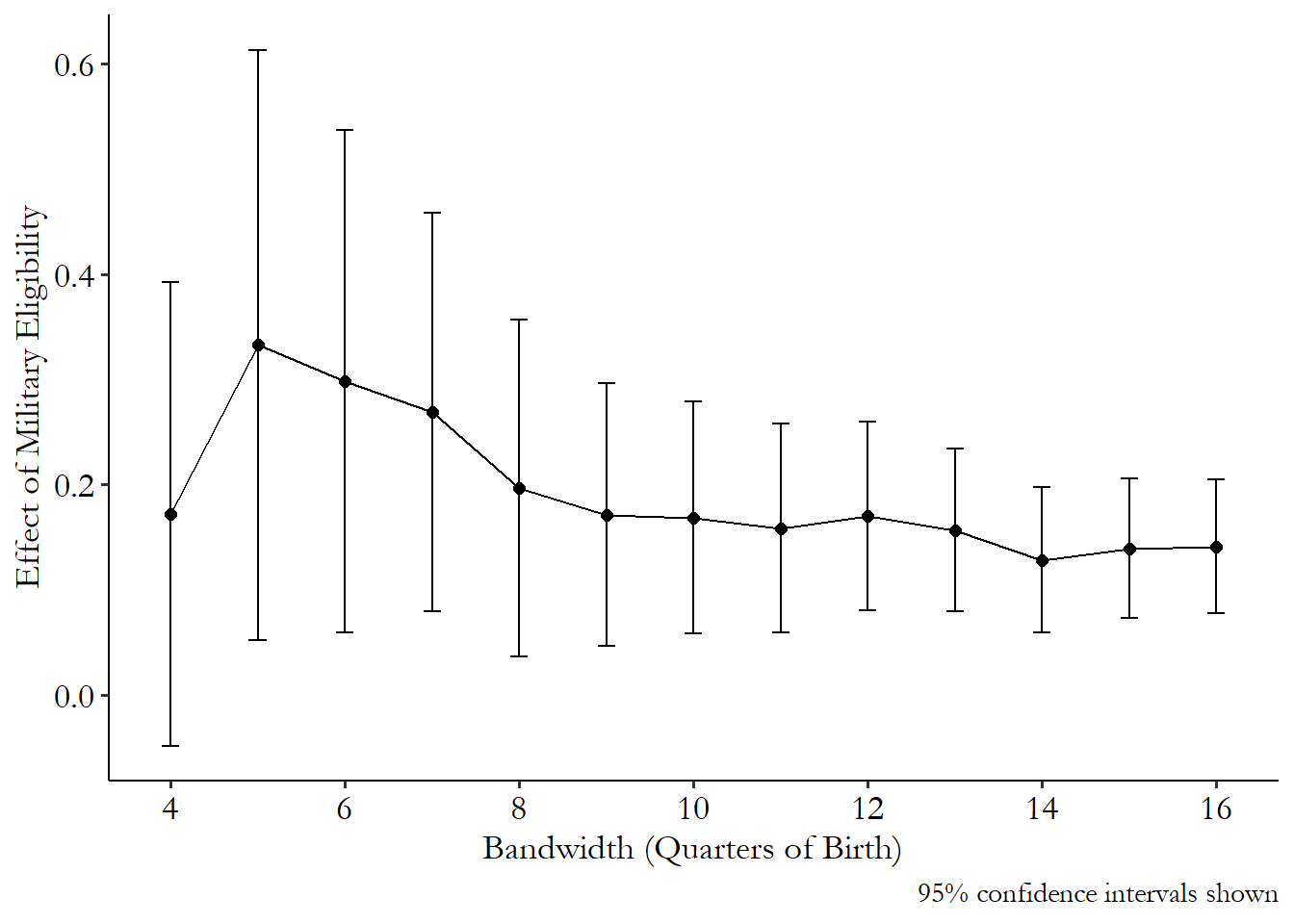
Double-BW 36.57 3 44 1.024e-11В строке LATE указано оптимально окно, Half-BW в 2 раза меньшего оптимального, а Double-BW в 2 раза больше.
Видим, что оценка совпала практически в точности с той, что мы получили вручную (в п. 2.2 получили эффект 9.753).
Далее воспользуемся встренной опцией расчета оптимальной ширины окна:
mod_rdd1 <- RDestimate(all ~ agecell, data=data, cutpoint = 21)
summary(mod_rdd1)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21)
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 1.6561 40 9.001 1.480 6.080 1.199e-09
Half-BW 0.8281 20 9.579 1.914 5.004 5.609e-07
Double-BW 3.3123 48 7.953 1.278 6.223 4.882e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 33.08 3 36 3.799e-10
Half-BW 29.05 3 16 2.078e-06
Double-BW 32.54 3 44 6.129e-11Оказалось, что оптимальное окно шире того, что мы использовали и равно 1.65.
Проверим на робастность с разными ядрами.
Веса из равномерного распределения одинаковые всех наблюдений, поэтму оценка почти совпадает с МНК, в остальных случаях оценка получилась выше и примерно равна 9.
Аналогичным образом мы можем проверить разрыв по всем видам причин.
mod_kernel1 <- RDestimate(all ~ agecell, data = data, cutpoint = 21, kernel = "rectangular")
summary(mod_kernel1)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
kernel = "rectangular")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 2.603 48 7.663 1.273 6.017 1.776e-09
Half-BW 1.302 32 9.094 1.498 6.072 1.267e-09
Double-BW 5.207 48 7.663 1.273 6.017 1.776e-09
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 29.47 3 44 2.651e-10
Half-BW 21.81 3 28 3.470e-07
Double-BW 29.47 3 44 2.651e-10mod_kernel2 <- RDestimate(all ~ agecell, data=data, cutpoint = 21, kernel = "triangular")
summary(mod_kernel2)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
kernel = "triangular")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 1.6561 40 9.001 1.480 6.080 1.199e-09
Half-BW 0.8281 20 9.579 1.914 5.004 5.609e-07
Double-BW 3.3123 48 7.953 1.278 6.223 4.882e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 33.08 3 36 3.799e-10
Half-BW 29.05 3 16 2.078e-06
Double-BW 32.54 3 44 6.129e-11mod_kernel3 <- RDestimate(all ~ agecell, data=data, cutpoint = 21, kernel = "epanechnikov")
summary(mod_kernel3)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
kernel = "epanechnikov")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 1.5417 38 9.079 1.480 6.135 8.502e-10
Half-BW 0.7708 18 9.450 1.998 4.730 2.242e-06
Double-BW 3.0833 48 7.779 1.271 6.121 9.298e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 29.18 3 34 3.205e-09
Half-BW 26.01 3 14 1.104e-05
Double-BW 30.70 3 44 1.457e-10mod_kernel4 <- RDestimate(all ~ agecell, data=data, cutpoint = 21, kernel = "quartic")
summary(mod_kernel4)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
kernel = "quartic")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 1.7603 42 9.046 1.469 6.157 7.415e-10
Half-BW 0.8801 22 9.445 1.950 4.845 1.269e-06
Double-BW 3.5205 48 7.842 1.271 6.168 6.904e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 34.26 3 38 1.350e-10
Half-BW 32.25 3 18 3.759e-07
Double-BW 31.29 3 44 1.100e-10mod_kernel5 <- RDestimate(all ~ agecell, data=data, cutpoint = 21, kernel = "gaussian")
summary(mod_kernel5)
Call:
RDestimate(formula = all ~ agecell, data = data, cutpoint = 21,
kernel = "gaussian")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 0.6064 48 9.068 1.490 6.084 1.172e-09
Half-BW 0.3032 48 9.431 1.838 5.132 2.869e-07
Double-BW 1.2128 48 8.027 1.279 6.279 3.418e-10
LATE ***
Half-BW ***
Double-BW ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 44.94 3 44 3.770e-13
Half-BW 73.65 3 44 0.000e+00
Double-BW 33.02 3 44 4.915e-11est<-c()
for (i in 1:3){
reg_rdd <- RDestimate(all ~ agecell, data = data, cutpoint = 21, bw=i, kernel = "triangular")
est[i]<-reg_rdd$est[1]
}se<-c()
for (i in 1:3){
reg_rdd <- RDestimate(all ~ agecell, data = data, cutpoint = 21, bw=i, kernel = "triangular")
se[i]<-reg_rdd$se[1]
}CIlow <- est - 1.96*se
CIup <- est + 1.96*selibrary(Hmisc)
errbar(x = c(1:3), y = est, yplus = CIup, yminus = CIlow, type = 'b')
Отсечка 20
data_new <- data[data$agecell < 21,]
mod_rdd_20 <- RDestimate(all ~ agecell, data = data_new, cutpoint = 20, kernel = "triangular")
summary(mod_rdd_20)
Call:
RDestimate(formula = all ~ agecell, data = data_new, cutpoint = 20,
kernel = "triangular")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 0.5553 14 0.7998 3.209 0.2493 0.8032
Half-BW 0.2777 7 -3.4455 2.663 -1.2940 0.1956
Double-BW 1.1107 24 0.7401 2.088 0.3544 0.7230
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 0.5695 3 10 0.7047
Half-BW 0.5823 3 3 0.6678
Double-BW 1.4173 3 20 0.5342Отсечка 20.5
data_new <- data[data$agecell < 21,]
mod_rdd_20.5 <- RDestimate(all ~ agecell, data = data_new, cutpoint = 20.5, kernel = "triangular")
summary(mod_rdd_20.5)
Call:
RDestimate(formula = all ~ agecell, data = data_new, cutpoint = 20.5,
kernel = "triangular")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 0.4051 10 2.3938 1.7961 1.3328 0.1826
Half-BW 0.2025 5 0.9779 0.7401 1.3212 0.1864
Double-BW 0.8101 16 0.4816 1.3249 0.3635 0.7162
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 1.4778 3 6 0.6246
Half-BW 1.6303 3 1 0.9813
Double-BW 0.9465 3 12 0.8978Отсечка 22
data_new2 <- data[data$agecell > 21,]
mod_rdd_22 <- RDestimate(all ~ agecell, data = data_new2, cutpoint = 22, kernel = "triangular")
summary(mod_rdd_22)
Call:
RDestimate(formula = all ~ agecell, data = data_new2, cutpoint = 22,
kernel = "triangular")
Type:
sharp
Estimates:
Bandwidth Observations Estimate Std. Error z value Pr(>|z|)
LATE 0.8808 22 -0.2917 2.125 -0.1373 0.8908
Half-BW 0.4404 11 -0.6552 3.344 -0.1959 0.8447
Double-BW 1.7616 24 0.2413 1.894 0.1274 0.8986
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F-statistics:
F Num. DoF Denom. DoF p
LATE 1.1277 3 18 0.72852
Half-BW 0.2613 3 7 0.29760
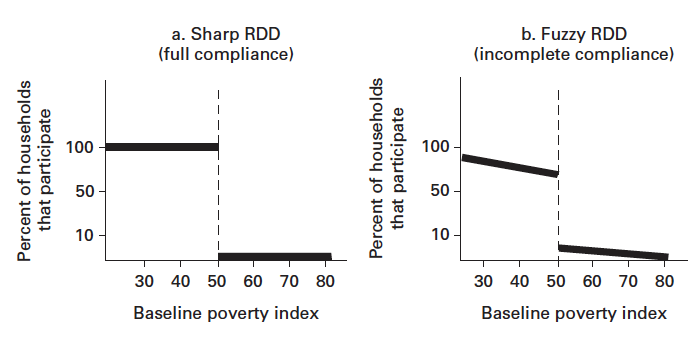
Double-BW 3.4606 3 20 0.07151Как известно, строгость правил смягчается необязательностью их исполнения, именно под этим слоганом работает метод размытой разрывной регрессии. В прошлом пукте мы предполагали, что все, у кого running variable больше cutoff, попадают в группу воздействия. Однако это не всегда бывает так. Бывает, что несмотря на предписание оказаться в группе воздействия, человек отказывается в этой опции или несмотря на то, что человеку предписано быть в контрольной группе, он находит возможность оказаться в группе воздействия. То есть мы снова столкнулись с ситуацией эндогенного тритмента.
Как устроен мир: \(Z->T->Y\)
Обозначения:
Предпосылки:
Когда выполнены все эти предпосылки, мы говорим, что эффект идентифицирован.
Если вы вспомните изученный ранее курс эконометрики, то с подобным вы уже встречались в теме LATE.
Пусть \(Z\) обозначает предписание исследователей о том, в какой группе длжно оказаться наблюдение, а \(T\) – в какой группе оно реально оказалось.
Подробнее про предпосылки:
Формула:
\(\mathrm{ITT}_T=\bar{T}_{Z=1}-\bar{T}_{Z=0}=P \text { (compliers) }\) (оценка первого шага), физический смысл – доля комплаеров в выборке
\(\mathrm{ITT}_Y=\bar{Y}_{Z=1}-\bar{Y}_{Z=0}\) (оценка второго шага), физический смысл – “оценка эффекта от намерения”, Intention to treat
\(\mathrm{TE}=\frac{\mathrm{ITT}_Y}{\mathrm{ITT}_T}=E(\tau \mid \text { Compliers })=\text { LATE }\) – тритмент эффект для комплаеров, численно совпадает с оценкой с помощью метода инструментальных переменных
\(\tau_{FRD} = \frac{\underset{R \rightarrow c+}{lim} E [Y|R] - \underset{R \rightarrow c-}{lim} E [Y|R]}{\underset{R \rightarrow c+}{lim} E [T|R] - \underset{R \rightarrow c-}{lim} E [T|R]}\)
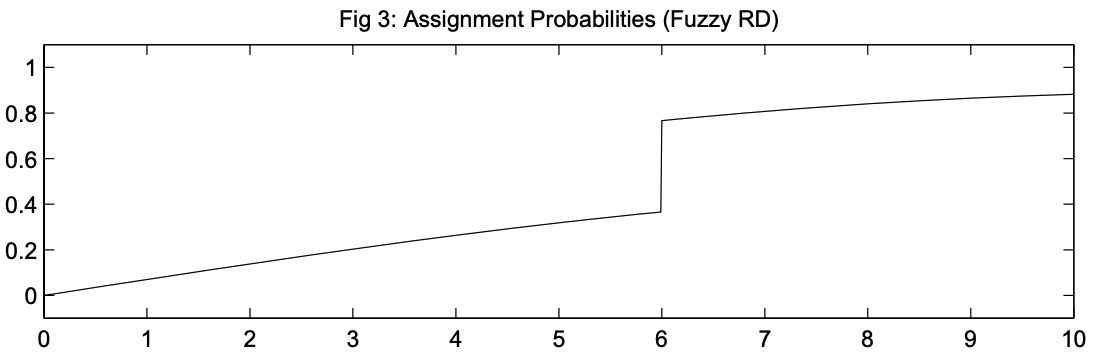
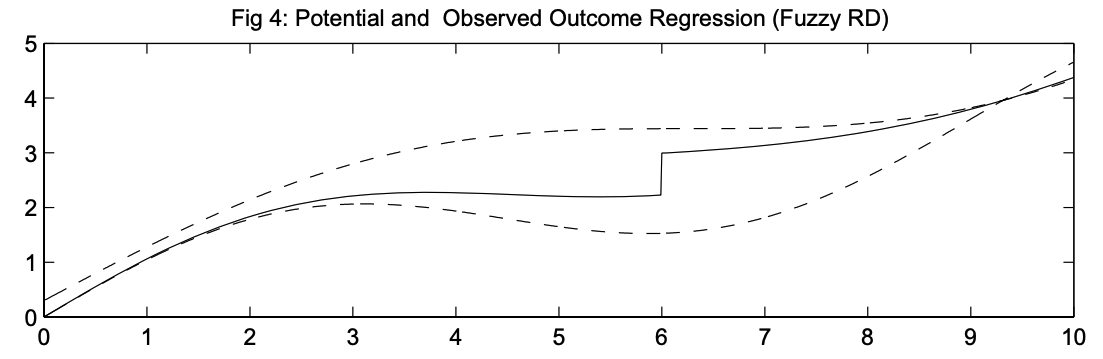
Рассмотрим пример на искусственных сгенерированных данных. В примере учащиеся сдают вступительный тест в начале учебного года. Если они набирают 70 баллов или меньше, им рекомендуется в течение года посещать дополнительные занятия. Итоговое решение о посещении занятий каждый учащийся принимает сам. В конце года студенты сдают выпускной тест. Задача: определеить эффект от дополнительных занятий на успеваемость учащихся.
library(readr)
df <- read_csv("regression_discontinuity_data/tutoring_program_fuzzy.csv")В нашем наборе всего 5 переменных
head(df, 10)# A tibble: 10 × 5
id entrance_exam tutoring tutoring_text exit_exam
<dbl> <dbl> <lgl> <chr> <dbl>
1 1 92.4 FALSE No tutor 78.1
2 2 72.8 FALSE No tutor 58.2
3 3 53.7 TRUE Tutor 62.0
4 4 98.3 FALSE No tutor 67.5
5 5 69.7 TRUE Tutor 54.1
6 6 68.1 TRUE Tutor 60.1
7 7 86.0 FALSE No tutor 73.1
8 8 85.7 TRUE Tutor 76.7
9 9 85.9 FALSE No tutor 57.8
10 10 89.5 FALSE No tutor 79.9Посмотрим, как распределены наши студенты вокруг порогового значения в 70 баллов
library(ggplot2)
ggplot(df, aes(x = entrance_exam, y = tutoring_text, color = entrance_exam <= 70)) +
geom_point(size = 1.5, alpha = 0.5) + # размер и прозрачность точек
geom_vline(xintercept = 70) + # cutoff
labs(x = "Баллы за экзамен", y = "Занимался дополнительно")
Точки слиплись в одну линию, это можно поправить, добавив специальный аргумент в функцию geom_point()
ggplot(df, aes(x = entrance_exam, y = tutoring_text, color = entrance_exam <= 70)) +
geom_point(size = 1.5, alpha = 0.5, # размер и прозрачность точек
position = position_jitter(width = 0, height = 0.25, seed = 1234)) + # разреженные точки
geom_vline(xintercept = 70) + # cutoff
labs(x = "Баллы за экзамен", y = "Занимался дополнительно")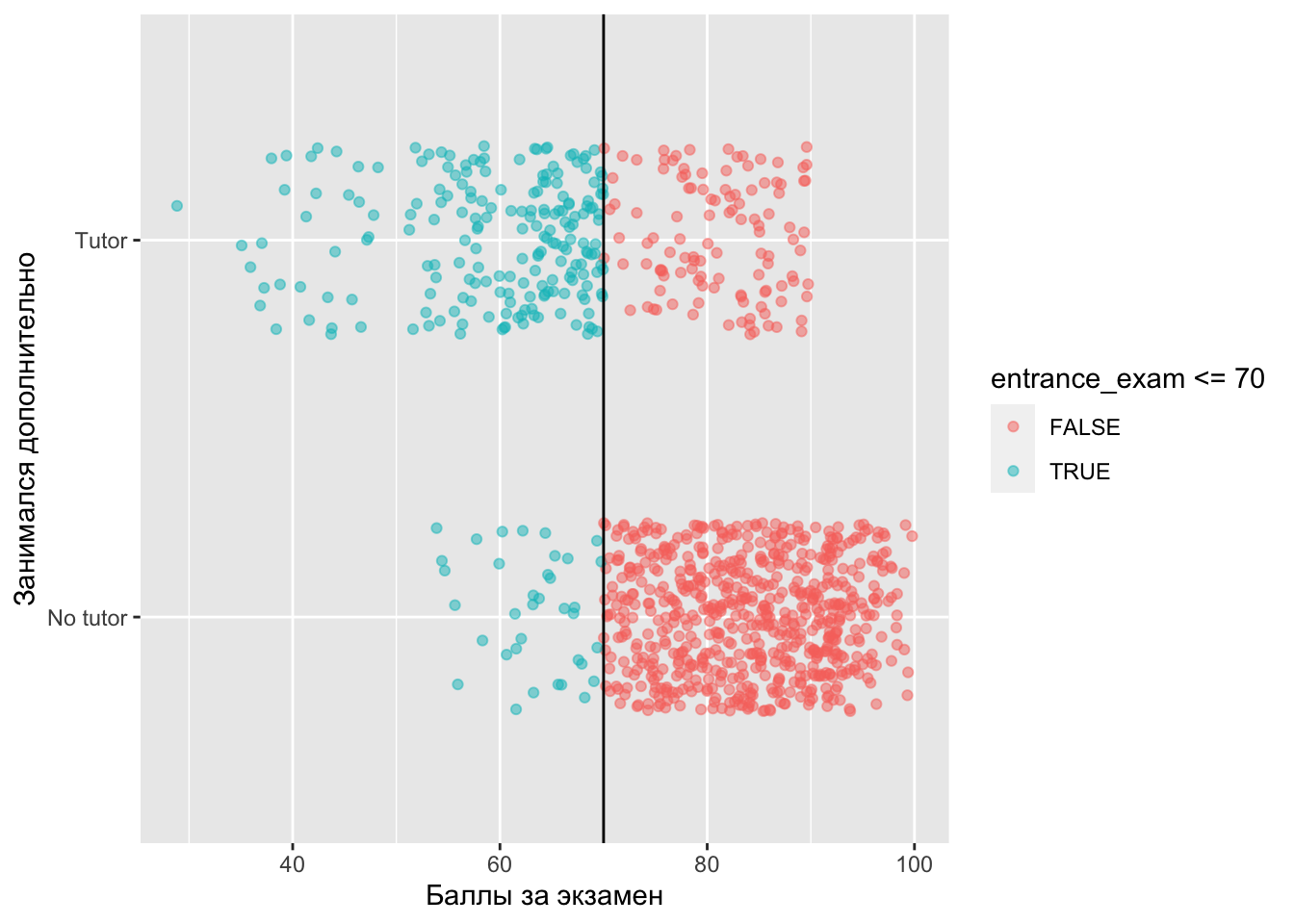
Видим, что есть студенты, которые ходили на дополнительные занятия, хотя тест им этого не показал, а есть те, кому надо было бы сходить, но они этого не сделали. Этого говорит о том, что мы находимся в ситуации нечеткой разрывной регресии. Студенты не всегда принимают решение в соотвествии с предписанием. Посмотрим, сколько таких студентов:
library(dplyr)
df %>%
group_by(tutoring, entrance_exam <= 70) %>%
summarise(count = n()) %>%
group_by(tutoring) %>%
mutate(prop = count / sum(count))# A tibble: 4 × 4
# Groups: tutoring [2]
tutoring `entrance_exam <= 70` count prop
<lgl> <lgl> <int> <dbl>
1 FALSE FALSE 646 0.947
2 FALSE TRUE 36 0.0528
3 TRUE FALSE 116 0.365
4 TRUE TRUE 202 0.635 То есть около 40% студентов приняли решение, которе противоречило предписанию.
Раньше мы строили следующий график:
ggplot(df, aes(x = entrance_exam, y = exit_exam, color = tutoring)) +
geom_point(size = 1, alpha = 0.5) +
geom_smooth(method = "lm") +
geom_vline(xintercept = 70) +
labs(x = "Баллы за вступительный тест", y = "Баллы за выпускной тест", color = "Дополнительные занятия")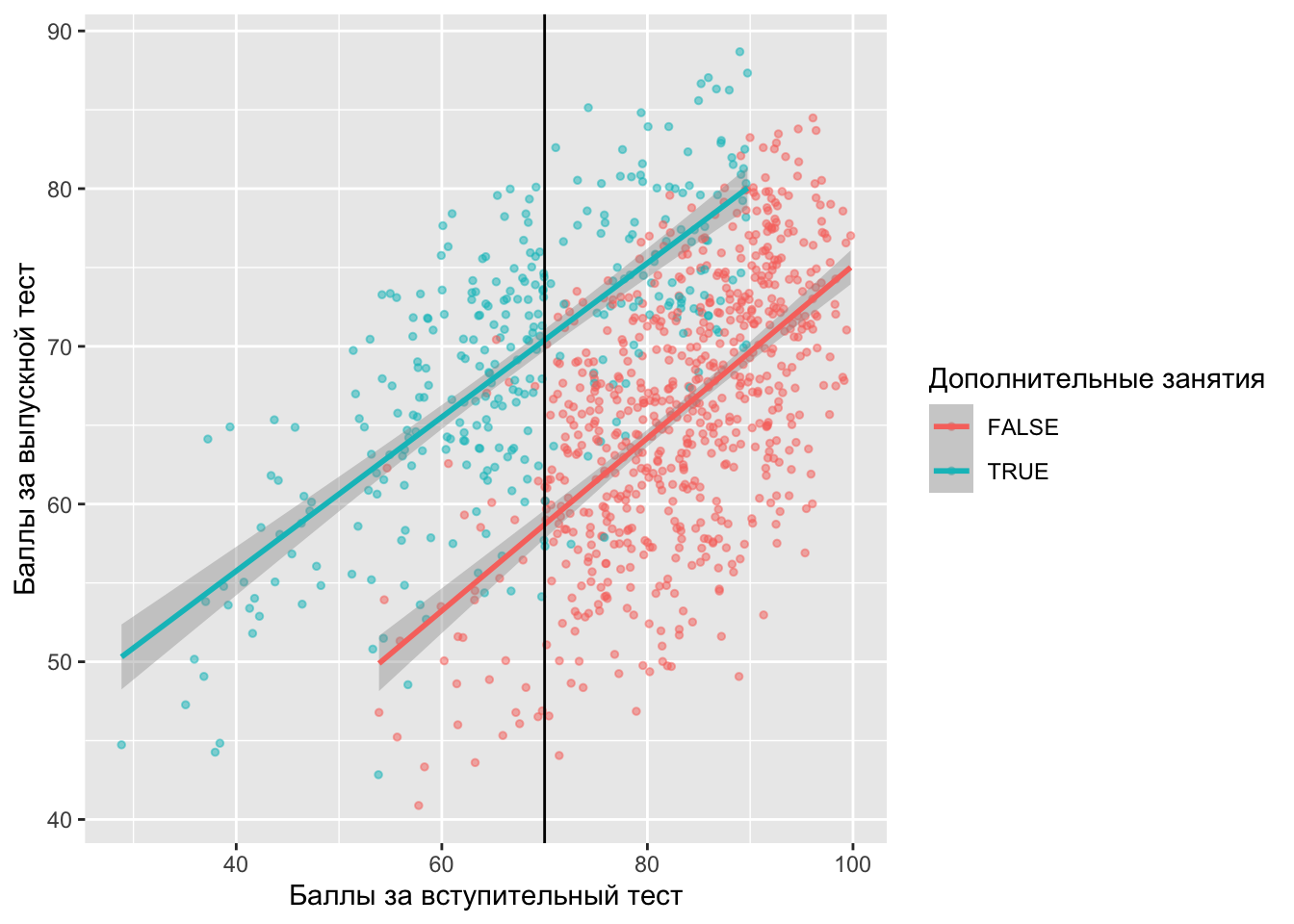
Сейчас мы так сделать не можем, поскольку наши тритмент и контрольные наблюдения находятся как справа, так и слева от отсечки. Раз ходили и не ходили все подряд, усовершенствуем наш график – посмотрим разрыв и по тем, кому надо было бы ходить, и по тем, кому не надо.
ggplot(df, aes(x = entrance_exam, y = exit_exam, color = tutoring)) +
geom_point(size = 1, alpha = 0.5) +
geom_smooth(data = filter(df, entrance_exam <= 70), method = "lm") +
geom_smooth(data = filter(df, entrance_exam > 70), method = "lm") +
geom_vline(xintercept = 70) +
labs(x = "Баллы за вступительный тест", y = "Баллы за выпускной тест", color = "Дополнительные занятия")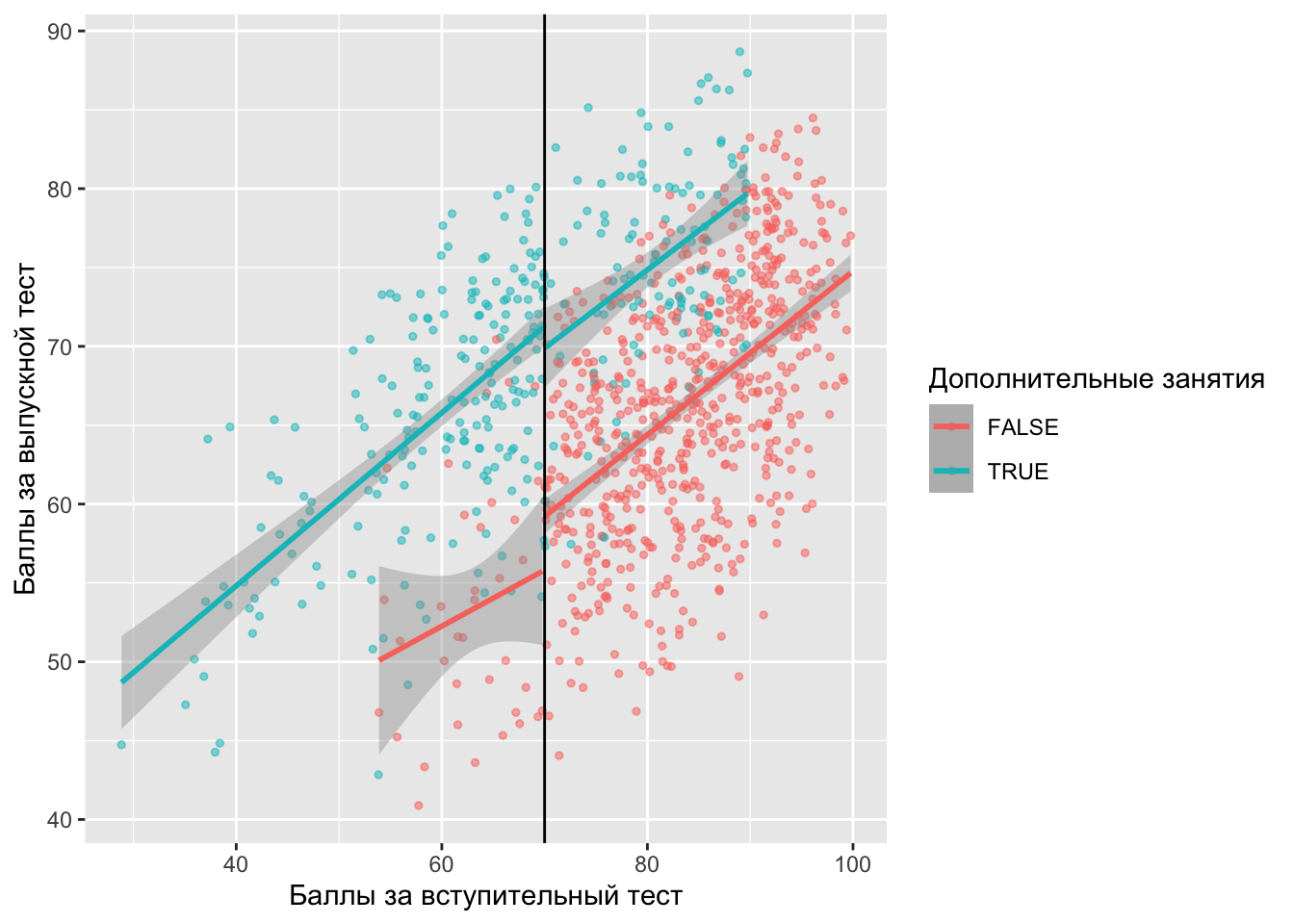
Видим разрыв в 70 баллах по-прежнему заметен, а также видим людей, которые использовали и не использовали дополнительные занятия по обе стороны отсечки. Другой способ взглянуть на это — построить гистограмму, показывающую вероятность участия в дополнительных занятия в зависимости от баллов вступительного теста.
Разобьем участников на интервалы по 5 баллов в зависимости от баллов за вступительный тест:
library(tidyr)
tutoring_with_bins <- df %>%
mutate(exam_binned = cut(entrance_exam, breaks = seq(0, 100, 5))) %>%
group_by(exam_binned, tutoring) %>%
summarise(n = n())
head(tutoring_with_bins)# A tibble: 6 × 3
# Groups: exam_binned [5]
exam_binned tutoring n
<fct> <lgl> <int>
1 (25,30] TRUE 1
2 (35,40] TRUE 10
3 (40,45] TRUE 11
4 (45,50] TRUE 9
5 (50,55] FALSE 3
6 (50,55] TRUE 20В таком виде считать вероятности неудобно, удобно совершать операции со столбиками. Поэтому переведем нашу таблицу из длинного в широкий вид:
wide_table <- tutoring_with_bins %>%
pivot_wider(names_from = "tutoring", values_from = "n", values_fill = 0) %>%
rename(tutor_yes = `TRUE`, tutor_no = `FALSE`)
wide_table# A tibble: 14 × 3
# Groups: exam_binned [14]
exam_binned tutor_yes tutor_no
<fct> <int> <int>
1 (25,30] 1 0
2 (35,40] 10 0
3 (40,45] 11 0
4 (45,50] 9 0
5 (50,55] 20 3
6 (55,60] 33 5
7 (60,65] 49 14
8 (65,70] 69 14
9 (70,75] 16 92
10 (75,80] 34 115
11 (80,85] 32 125
12 (85,90] 34 131
13 (90,95] 0 134
14 (95,100] 0 49И рассчитаем вероятности:
prob_table <- wide_table %>% mutate(prob_tutoring = tutor_yes / (tutor_yes + tutor_no))
prob_table# A tibble: 14 × 4
# Groups: exam_binned [14]
exam_binned tutor_yes tutor_no prob_tutoring
<fct> <int> <int> <dbl>
1 (25,30] 1 0 1
2 (35,40] 10 0 1
3 (40,45] 11 0 1
4 (45,50] 9 0 1
5 (50,55] 20 3 0.870
6 (55,60] 33 5 0.868
7 (60,65] 49 14 0.778
8 (65,70] 69 14 0.831
9 (70,75] 16 92 0.148
10 (75,80] 34 115 0.228
11 (80,85] 32 125 0.204
12 (85,90] 34 131 0.206
13 (90,95] 0 134 0
14 (95,100] 0 49 0 Теперь можем их нарисовать:
ggplot(prob_table, aes(x = exam_binned, y = prob_tutoring)) +
geom_col() +
geom_vline(xintercept = 8.5, color = 'red', size = 1, linetype = "dashed") + # потому что между 8 и 9 столбиком
labs(x = "Результаты вступительного теста", y = "Доля людей, которые ходили на дополительные занятия")
Видим, что 100% людей, набравших на экзамене от 25 до 50 баллов, занимались дополнительно, это хорошо. Затем вероятность занятий падает примерно до 80% вплоть до точки отсечения. После 70 баллов вероятность посещения дополнительных занятий составляет 10–15%. В случае четкой регресии каждый столбик слева от точки отсечения был бы 100%, а каждый столбец справа был бы 0%. Видим, что у нас это не так.
Иногда в RDD используют центрированные данные, чтобы оценивать эффект в терминах отклонения
df <- df %>%
mutate(entrance_centered = entrance_exam - 70, # центрируем данные
below_cutoff = entrance_exam <= 70) # инструмент -- Z
head(df, 10)# A tibble: 10 × 7
id entrance_exam tutoring tutoring_text exit_exam entrance_centered
<dbl> <dbl> <lgl> <chr> <dbl> <dbl>
1 1 92.4 FALSE No tutor 78.1 22.4
2 2 72.8 FALSE No tutor 58.2 2.77
3 3 53.7 TRUE Tutor 62.0 -16.3
4 4 98.3 FALSE No tutor 67.5 28.3
5 5 69.7 TRUE Tutor 54.1 -0.288
6 6 68.1 TRUE Tutor 60.1 -1.93
7 7 86.0 FALSE No tutor 73.1 16.0
8 8 85.7 TRUE Tutor 76.7 15.7
9 9 85.9 FALSE No tutor 57.8 15.9
10 10 89.5 FALSE No tutor 79.9 19.5
# ℹ 1 more variable: below_cutoff <lgl>Теперь у нас есть новый столбец below_cutoff, который мы будем использовать в качестве инструмента. В большинстве случаев это будет то же самое, что и колонка tutoring, поскольку большинство людей соблюдают правила. Прежде чем использовать инструмент, сначала оценим модель с четким дизайном разрыной регресии. Используем окно в 10 баллов
model_sharp <- lm(exit_exam ~ entrance_centered + tutoring,
data = subset(df, entrance_centered >= -10 & entrance_centered <= 10))
summary(model_sharp)
Call:
lm(formula = exit_exam ~ entrance_centered + tutoring, data = subset(df,
entrance_centered >= -10 & entrance_centered <= 10))
Residuals:
Min 1Q Median 3Q Max
-16.9772 -4.3138 0.3467 4.7589 13.5556
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59.2740 0.5029 117.872 < 2e-16 ***
entrance_centered 0.5113 0.0665 7.688 1.17e-13 ***
tutoringTRUE 11.4845 0.7443 15.430 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.465 on 400 degrees of freedom
Multiple R-squared: 0.3732, Adjusted R-squared: 0.3701
F-statistic: 119.1 on 2 and 400 DF, p-value: < 2.2e-16Коэффициент tutoringTRUE показывает размер разрыва, равного 11,5 баллов. Это означает, что участие в дополнительных занятиях создает премию на выпускном тесте. Но в действительности это неверно. Это не четкий дизайн, пэтому оценка такой регрессии является некорректной и приводит к смещению оценок. Вместо этого нам нужно воспользоваться двухшаговым методом наименьших квадратов.
\[ \begin{aligned} & \widehat{\text { Tutoring program }}=\gamma_0+\gamma_1 \text { Entrance exam score }_{\text {centered }}+\gamma_2 \text { Below cutoff }+\omega \\ & \text { Exit exam }=\beta_0+\beta_1 \text { Entrance exam score }_\text { centered }+\beta_2 \widehat{\text { Tutoring program }}+\varepsilon \\ & \end{aligned} \]
Это можно было бы сделать вручную двумя регрессиями, но мы сразу воспользуемся пакетным решением:
library('ivreg')
model_fuzzy <- ivreg(exit_exam ~ entrance_centered + tutoring | # R + T
entrance_centered + below_cutoff, # R + Z
data = subset(df, entrance_centered >= -10 & entrance_centered <= 10))
summary(model_fuzzy)
Call:
ivreg(formula = exit_exam ~ entrance_centered + tutoring | entrance_centered +
below_cutoff, data = subset(df, entrance_centered >= -10 &
entrance_centered <= 10))
Residuals:
Min 1Q Median 3Q Max
-17.1782 -4.5367 0.3994 4.8710 13.3955
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 60.1414 0.9622 62.503 < 2e-16 ***
entrance_centered 0.4366 0.0972 4.492 9.24e-06 ***
tutoringTRUE 9.7410 1.8074 5.390 1.21e-07 ***
Diagnostic tests:
df1 df2 statistic p-value
Weak instruments 1 400 83.033 <2e-16 ***
Wu-Hausman 1 399 1.139 0.286
Sargan 0 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.509 on 400 degrees of freedom
Multiple R-Squared: 0.3646, Adjusted R-squared: 0.3615
Wald test: 14.58 on 2 and 400 DF, p-value: 7.746e-07 library(estimatr)
model_fuzzy2 <- iv_robust(exit_exam ~ entrance_centered + tutoring | entrance_centered + below_cutoff,
data = filter(df, entrance_centered >= -10 & entrance_centered <= 10)
)
summary(model_fuzzy2)
Call:
iv_robust(formula = exit_exam ~ entrance_centered + tutoring |
entrance_centered + below_cutoff, data = filter(df, entrance_centered >=
-10 & entrance_centered <= 10))
Standard error type: HC2
Coefficients:
Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
(Intercept) 60.1414 1.0177 59.098 9.747e-200 58.1407 62.1420 400
entrance_centered 0.4366 0.0993 4.397 1.407e-05 0.2414 0.6318 400
tutoringTRUE 9.7410 1.9118 5.095 5.384e-07 5.9825 13.4996 400
Multiple R-squared: 0.3646 , Adjusted R-squared: 0.3615
F-statistic: 13.06 on 2 and 400 DF, p-value: 3.19e-06tidy(model_fuzzy2) term estimate std.error statistic p.value conf.low
1 (Intercept) 60.1413558 1.01765573 59.097939 9.746624e-200 58.1407338
2 entrance_centered 0.4366281 0.09929619 4.397229 1.407213e-05 0.2414205
3 tutoringTRUE 9.7410444 1.91184891 5.095091 5.384163e-07 5.9825170
conf.high df outcome
1 62.1419778 400 exit_exam
2 0.6318357 400 exit_exam
3 13.4995718 400 exit_examА теперь оценим разрыв специальным подходящим для этого пакетом и с ядерными оценками плотности:
library(rdd)
model_fuzzy1 <- RDestimate(exit_exam ~ entrance_exam + tutoring, # R + T -- для fuzzy задается вторым регрессором T
data = df, cutpoint = 70, kernel = "triangular")
summary(model_fuzzy )
Call:
ivreg(formula = exit_exam ~ entrance_centered + tutoring | entrance_centered +
below_cutoff, data = subset(df, entrance_centered >= -10 &
entrance_centered <= 10))
Residuals:
Min 1Q Median 3Q Max
-17.1782 -4.5367 0.3994 4.8710 13.3955
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 60.1414 0.9622 62.503 < 2e-16 ***
entrance_centered 0.4366 0.0972 4.492 9.24e-06 ***
tutoringTRUE 9.7410 1.8074 5.390 1.21e-07 ***
Diagnostic tests:
df1 df2 statistic p-value
Weak instruments 1 400 83.033 <2e-16 ***
Wu-Hausman 1 399 1.139 0.286
Sargan 0 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.509 on 400 degrees of freedom
Multiple R-Squared: 0.3646, Adjusted R-squared: 0.3615
Wald test: 14.58 on 2 and 400 DF, p-value: 7.746e-07 library(rdrobust)
model_frdd_2 <- rdrobust(y = df$exit_exam, x = df$entrance_exam, c = 70,
fuzzy = df$tutoring) # T
summary(model_frdd_2)Fuzzy RD estimates using local polynomial regression.
Number of Obs. 1000
BW type mserd
Kernel Triangular
VCE method NN
Number of Obs. 238 762
Eff. Number of Obs. 170 347
Order est. (p) 1 1
Order bias (q) 2 2
BW est. (h) 12.985 12.985
BW bias (b) 19.733 19.733
rho (h/b) 0.658 0.658
Unique Obs. 238 762
First-stage estimates.
=============================================================================
Method Coef. Std. Err. z P>|z| [ 95% C.I. ]
=============================================================================
Conventional -0.708 0.073 -9.751 0.000 [-0.850 , -0.565]
Robust - - -8.424 0.000 [-0.907 , -0.565]
=============================================================================
Treatment effect estimates.
=============================================================================
Method Coef. Std. Err. z P>|z| [ 95% C.I. ]
=============================================================================
Conventional 9.683 1.893 5.116 0.000 [5.973 , 13.393]
Robust - - 4.258 0.000 [5.210 , 14.095]
=============================================================================Сравним оценки
library(modelsummary)
library(kableExtra)
modelsummary(list("Sharp -- lm" = model_sharp,
"Fuzzy -- ivreg" = model_fuzzy),
gof_omit = 'IC|Log|Adj|p\\.value|statistic|se_type',
stars = TRUE) %>%
row_spec(5, background = "#F5ABEA")| Sharp -- lm | Fuzzy -- ivreg | |
|---|---|---|
| (Intercept) | 59.274*** | 60.141*** |
| (0.503) | (0.962) | |
| entrance_centered | 0.511*** | 0.437*** |
| (0.067) | (0.097) | |
| tutoringTRUE | 11.484*** | 9.741*** |
| (0.744) | (1.807) | |
| Num.Obs. | 403 | 403 |
| R2 | 0.373 | 0.365 |
| F | 119.103 | |
| RMSE | 6.44 | 6.48 |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |